今天,我们宣布了新闻API增强实体的主要版本,对我们的实体功能和搜索功能进行了全面更新,提高了覆盖率和准确性。
这个版本包括:
- 一种新的实体识别模型(Entities V3)
- 增强的搜索功能
- 实体级情感分析特性
这些特性结合在一起提供了改进的实体体验,以帮助您从我们的新闻API中发现更高质量的数据和业务见解。
是什么改变了?
.png)
你可以在我们文档的通用工作流部分阅读更多关于使用V3实体模型的信息:使用实体V3.你也可以在这里观看增强实体的演示.
实体是什么?
在我们深入探讨增强实体提供什么之前,让我们快速回顾一下实体是什么,以及它们在此背景下为什么重要。实体是"具有独特和独立存在的事物"。换句话说,从理论上讲,当你在海量的全球每日新闻中搜索时,这些信息应该很容易被识别出来,比如人、地方、公司、产品和概念。
当两个或两个以上的实体拼写相同但含义不同时,就会出现问题,例如apple the fruit和apple the company。在这种情况下,传统的关键字搜索将返回该拼写的所有实例的结果,使您需要筛选大量不相关的新闻文章,从而提供不那么准确的结果,从而影响模型和工作流。当一个实体以多种表面形式被提及时,例如General Motors(通用汽车)和GM(通用汽车),会导致文章被完全遗漏。
.png)
利用AYLIEN的自然语言处理(NLP)技术解决了这一问题。在名为命名实体消除歧义的过程中,它提供了关于被引用的实体的准确预测。通过将实体与文章的其余部分联系起来,并将其与知识库(Wikidata)匹配,AYLIEN可以判断文章是指城市苏黎世,还是保险集团苏黎世。因此,基于实体的搜索通过提高返回的新闻文章的准确性和相关性大大减少了噪声。此外,即使使用不同的表面形式,AYLIEN也能正确识别每个提及的实体,例如大都会人寿、MLIC和大都会人寿保险公司,确保没有遗漏任何提及。
增强实体的好处是什么?
改进的实体识别和消歧
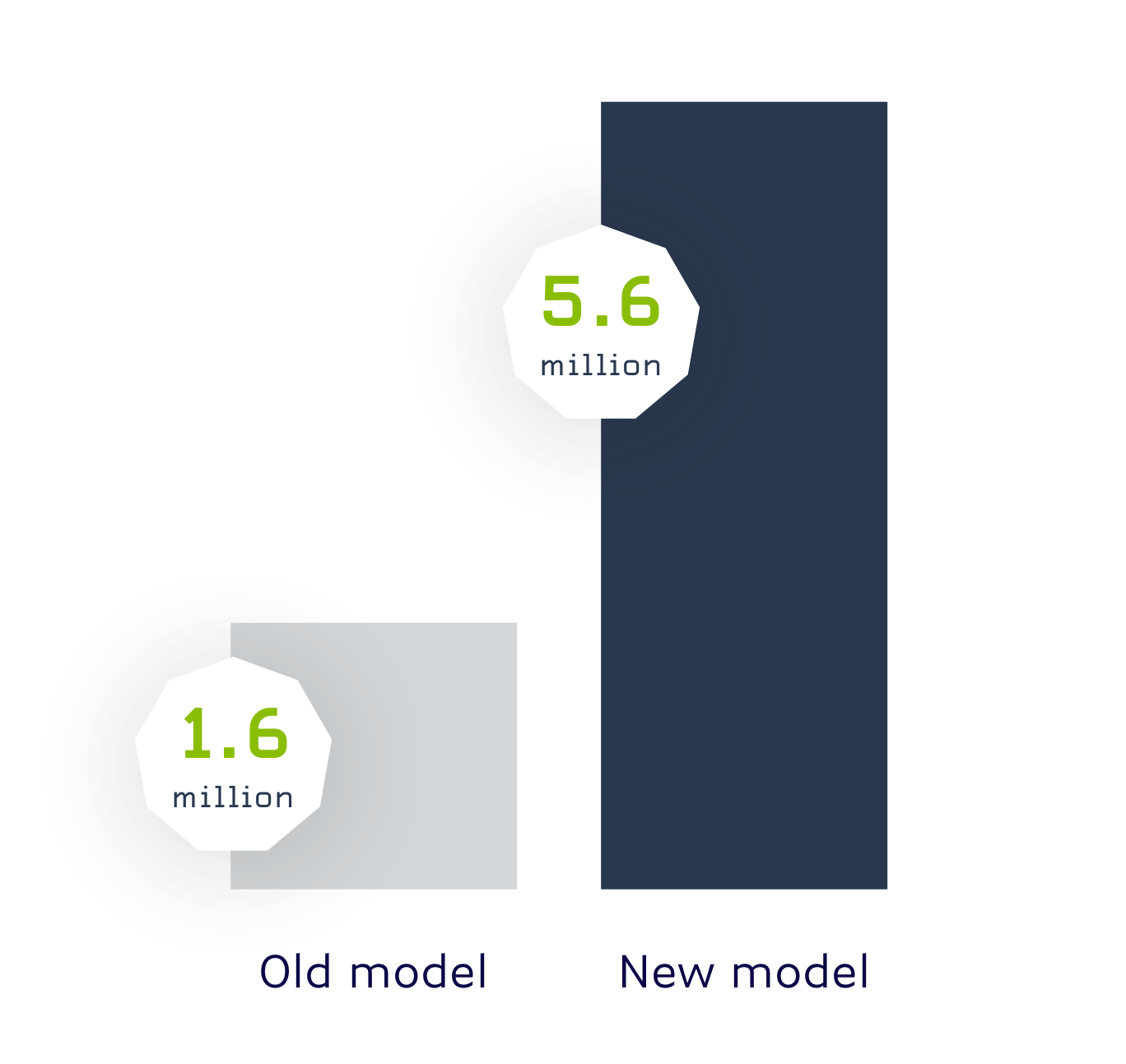
我们的新实体模型将识别的实体数量从上一个模型的不到200万个大幅提高到560万个左右。我们还加强了在金融服务领域的表现,我们对标准普尔500和罗素2000公司实体的识别精度达到95%。在与竞争对手的新闻API提供商进行测试时,我们的模型也更加准确,在某些情况下,我们在一组样本文章中识别实体的数量方面比竞争对手高出65%。
让我们来看一个例子:搜索标题中提到“Square”支付公司的文章可能会令人沮丧。Square是一个常见的单词,传统的搜索会返回很多噪声。《Enhanced Entities》消除了这种干扰,它提供的文章是“明年1月将在广场发布一项新的支付功能”,而不是“梅西百货(Macy’s)在时代广场开设新店”。
增强了实体类型的搜索
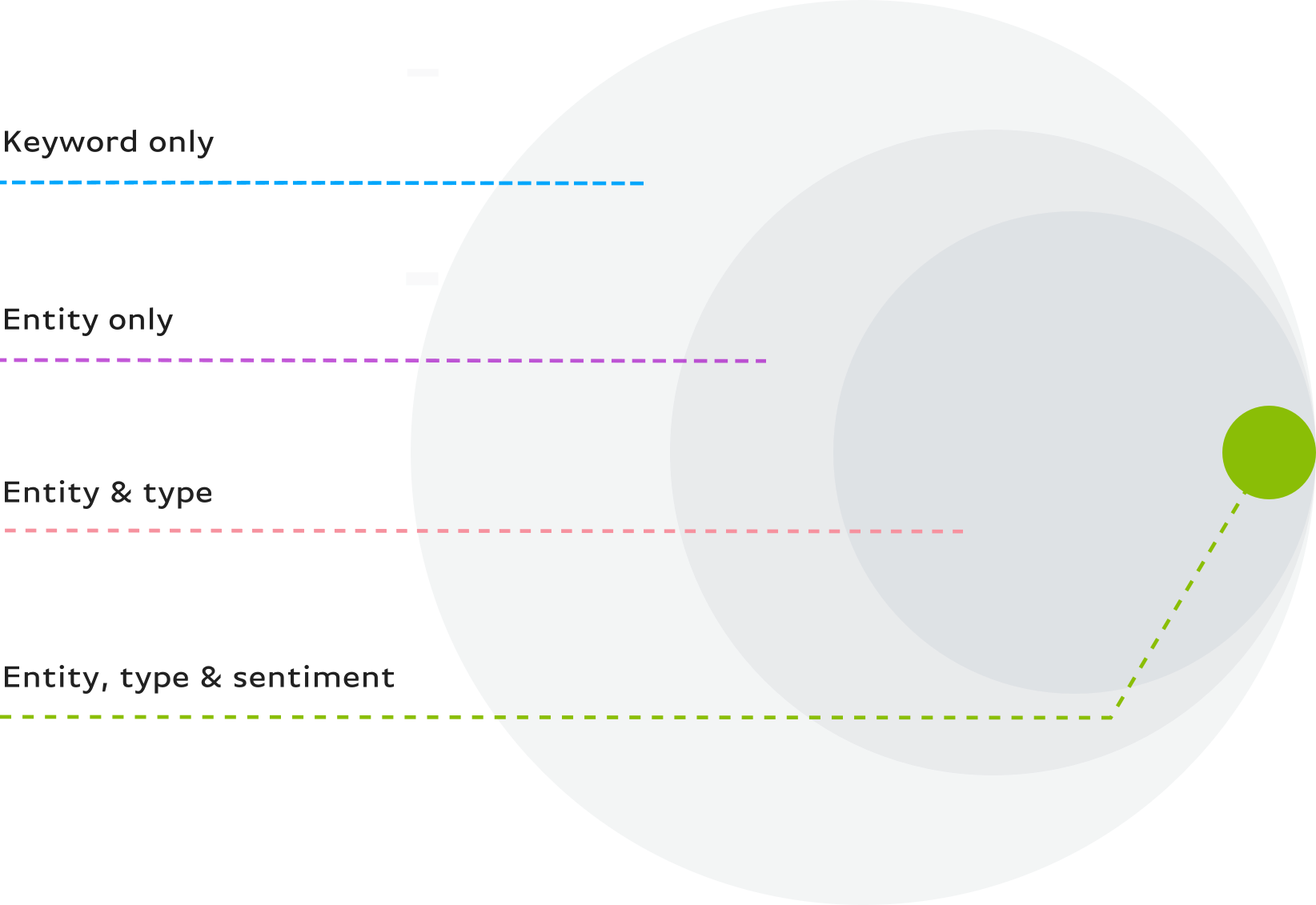
增强的搜索功能使用户能够在查询中结合两个或更多与实体相关的参数来确定他们正在寻找的新闻,减少了无关结果和误报的干扰。它包括情感、类型和文档元素(标题/正文)的参数。我们还添加了通过查询实体的股票行情或Wikipedia/Wikidata链接来识别实体的功能,以进一步提高准确性。
这里有一个简单的例子:搜索越具体,你的结果可能就越相关。有了这个逻辑,在Enhanced Entities中组合实体参数将会给你更准确的结果。例如,在提到特斯拉汽车(Tesla Motors)的文章中,搜索对埃隆·马斯克(Elon Musk)的负面描述(输入“人类”),同时搜索对特斯拉汽车(Tesla Motors)的正面描述(输入“组织”),就会得到你想要的结果。
实体级情感分析(ELSA)

现在,文章中提到的每一个实体都将得到一个情绪预测。它是这样工作的:我们的NLP引擎在每篇文章中识别实体候选者,然后分析它包含的完整句子,以预测其情感极性(积极、消极或中性)。如果实体被多次提及,每一次提及都将被评估情绪,并计算整个标题或主体的平均值。还提供了一个置信度评分,以显示模型对预测的置信度。
让我们用一个简单的例子:如果没有ELSA,搜索提到“唐纳德·特朗普”的文章(无论是积极的还是消极的)可能没有你想象的那么容易。在文档层面上依赖情绪分析可能会得到一篇整体负面的文章,但会以正面的方式提到特朗普(反之亦然)。谢天谢地,ELSA消除了这种模糊性,从而进行更精确的情感分析。
最终,增强的实体使新闻API用户能够进行更准确的搜索,以发现对他们重要的新闻。您可以阅读更多关于如何利用我们的增强实体功能文档而且迁移向导,在这里观看演示.如果你还没有,你可以注册一个免费试用这里是AYLIEN的新闻API.





消息灵通
我们会不时通过电子邮件与您联系我们的产品和服务。